[Aug. 2025] [Award] Our work CROSS: Enable AI Accelerator for Homomorphic Encryption won the GT NEXT Award in recognition of our commitment to research and development that has the potential to significantly contribute to societal betterment! Go Yellow Jackets!
[Mar. 2025] [Tool] LayoutLoop from FEATHER [ISCA'24] has been integrated into NVlabs/Timeloop, details could be found at this PR and this slide, enjoy precise layout modeling!
[Nov. 2024] [Teaching] I gave a guest lecture of FEATHER at the "Advanced Computer Architecture for Machine Learning" course hosted by Prof. Tony Geng.
[Aug. 2024] [Award] I was selected as the student for ACE Newsletter highlight by SRC!
[Aug. 2024] [Talk] I give a talk on FEATHER at SRC Liaison Meeting of ACE Center!
[Aug. 2024] [Career] I join Google as a student researcher in Phazon team of PSS, more realistic privacy-preserving acceleration are coming, stay tuned!
[Jul. 2024] [Talk] I give a talk on FEATHER at NVidia (HQ) and NVidia (Westford)!
[Jun. 2024] [Talk] We debut FEATHER A Reconfigurable Accelerator with Data Reordering Support for Low-Cost On-Chip Dataflow Switching at ISCA, Buenos Aires!
[May. 2024] [Talk] I give a talk on FEATHER at MIT
[May. 2024] [Award] I am selected as "ML and System Rising Star" by ML Commons, excited to meet you all at Nvidia HQ at Jul 15~16.
[May. 2024] [Award] Our team "CipherFlitFort" is awarded Startup Launch by CreateX at Georgia Tech, Go Jackets!
[Apr. 2024] [Award] I am selected as DAC Young Fellow for DAC 2024.
[Mar. 2024] [Paper] Our work FEATHER: A Reconfigurable Accelerator with Data Reordering Support for Low-Cost On-Chip Dataflow Switching is accepted to the International Symposium on Computer Architecture (ISCA'24).
[Feb. 2024] [Paper] Our work SmartPAF: Accurate Low-Degree Polynomial Approximation of Non-polynomial Operators for Fast Private Inference in Homomorphic Encryption is accepted to the Seventh Conference on Machine Learning and Systems (MLSys'24).
[Feb. 2024] [Service] We started course 6.192 Constructive Computer Architecture in three schools together this year (MIT, EPFL, GaTech) - recordings available online, Go Architects!
[Nov. 2023] [Service] I join Computer Architecture Student Association ( CASA ) steering team, from the architects for the architects.
[Oct. 2023] [Talk] I gave a talk on SUSHI and PAF-FHE at HAN Lab @ MIT.
[Sep. 2023] [Award] I won Best Poster Award for presenting our work SUSHI at (IAP Workshop@MIT).
[Sep. 2023] [Paper] Our work Hardware-Software co-design for real-time latency-accuracy navigation in tinyML applications is accepted to the Journal (IEEE micro).
[Sep. 2023] [Career] I join MIT as a visiting researcher in CSAIL hosted by Dr. Arvind.
[Aug. 2023] [Paper] Our work SNATCH: Stealing Neural Network Architecture from ML Accelerator in Intelligent Sensors is accepted to the IEEE SENSORS conference (SENSORS'23).
[Jul. 2023] [Paper] Our work On Continuing DNN Accelerator Architecture Scaling Using Tightly-coupled Compute-on-Memory 3D ICs is accepted to the IEEE Transactions on Very Large Scale Integration Systems (TVLSI'23).
[Apr. 2023] [Paper] Our work FPGA-Based High-Performance Real-Time Emulation of Radar System using Direct Path Compute Model accepted to the International Microwave Symposium (IMS'23).
[Mar. 2023] [Talk] I give a talk on Enable Best ML Inference and Training: A systematic Approach at EIC Lab @ Georgia Tech.
[Mar. 2023] [Paper] Our work A High Performance Computing Architecture for Real-Time Digital Emulation of RF Interactions accepted to the In Proc of IEEE Radar Conference (RadarConf'23).
[Jul. 2022] [Talk] I present our work FastSwtich: Enabling Real-time DNN Switching via Weight-Sharing at the 2nd Architecture, Compiler, and System Support for Multi-model DNN Workloads Workshop Workshop @ ISCA'23 .
[Apr. 2022] [Award] I receive Finalist in Qualcomm Innovation Fellowship, thank you Qualcomm!
[Mar. 2022] [Award] I win 2nd place in SCS Poster Competition at Georgia Tech, thank you SCS!
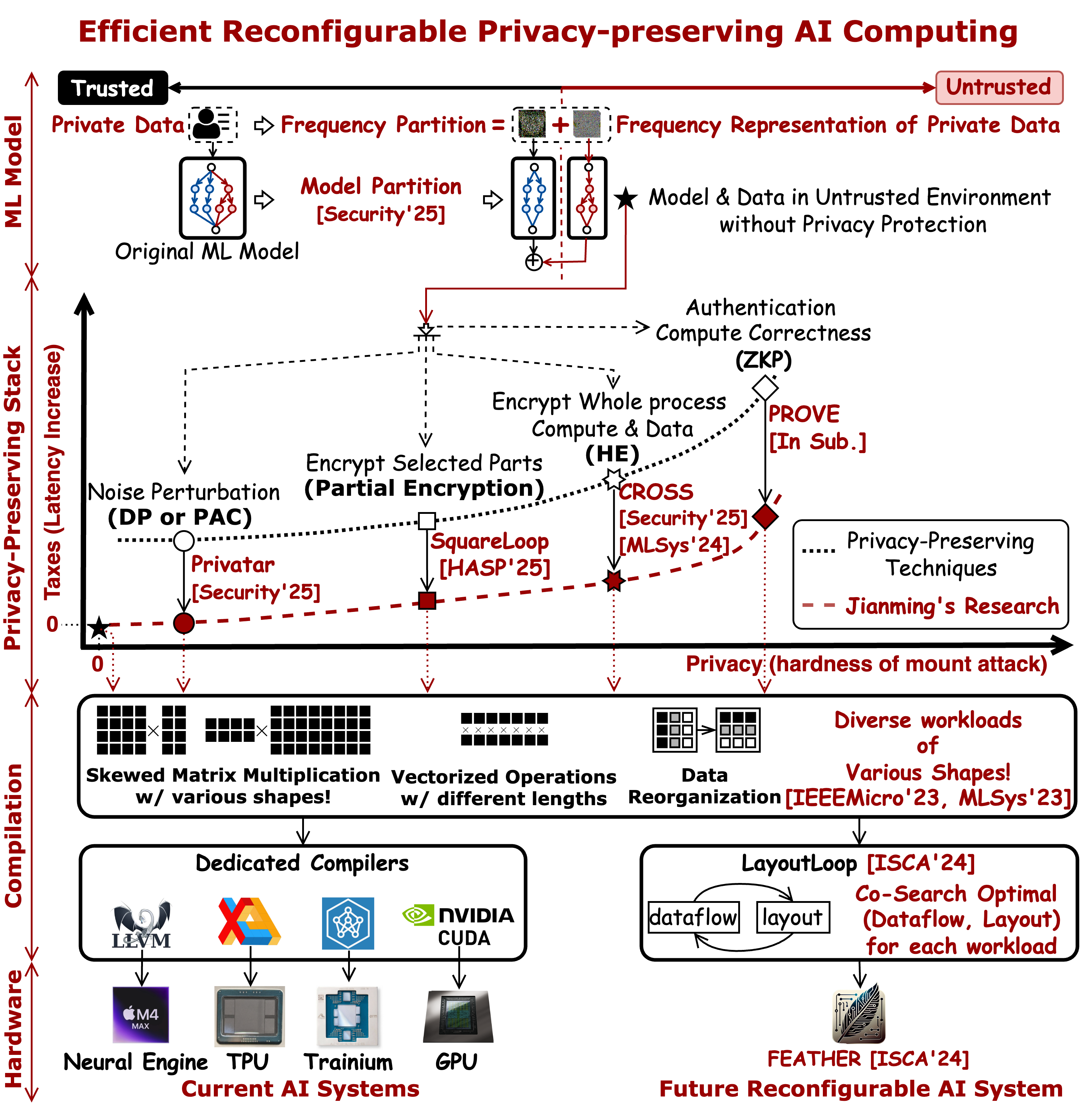
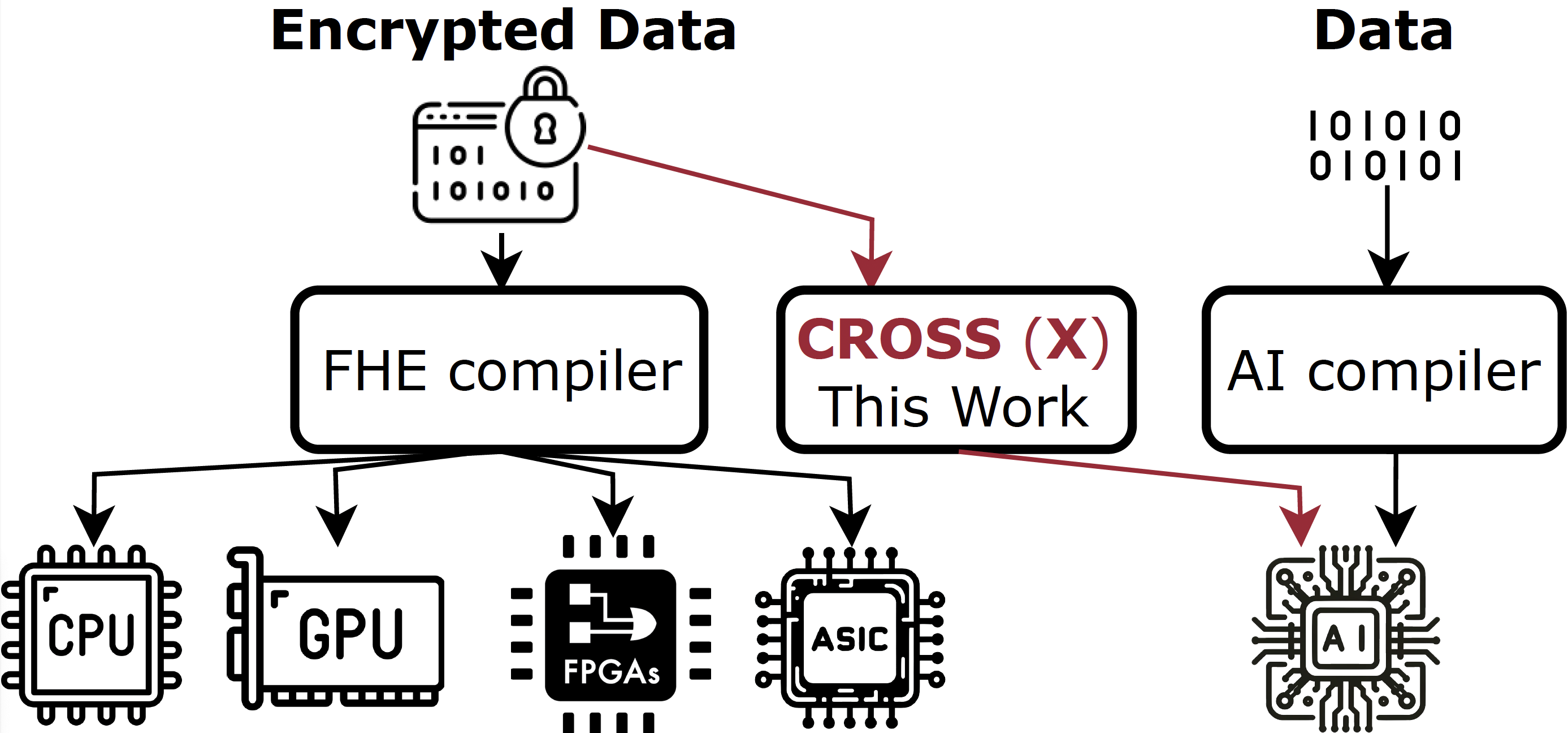
Cloud-based services are making the outsourcing of sensitive client data increasingly common. Although homomorphic encryption (HE) offers strong privacy guarantee, it requires substantially more resources than computing on plaintext, often leading to unacceptably large latencies in getting the results. HE accelerators have emerged to mitigate this latency issue, but with the high cost of ASICs. In this paper we show that HE primitives can be converted to AI operators and accelerated on existing ASIC AI accelerators, like TPUs, which are already widely deployed in the cloud. Adapting such accelerators for HE requires (1) supporting modular multiplication, (2) high-precision arithmetic in software, and (3) efficient mapping on matrix engines. We introduce the CROSS compiler (1) to adopt Barrett reduction to provide modular reduction support using multiplier and adder, (2) Basis Aligned Transformation (BAT) to convert high-precision multiplication as low-precision matrix-vector multiplication, (3) Matrix Aligned Transformation (MAT) to covert vectorized modular operation with reduction into matrix multiplication that can be efficiently processed on 2D spatial matrix engine. Our evaluation of CROSS on a Google TPUv4 demonstrates significant performance improvements, with up to 161x and 5x speedup compared to the previous work on many-core CPUs and V100. The kernel-level codes are open-sourced at https://github.com/google/jaxite.git.
@misc{tong2025leveragingasicaichips,
title={Leveraging ASIC AI Chips for Homomorphic Encryption},
author={Jianming Tong and Tianhao Huang and Leo de Castro and Anirudh Itagi and Jingtian Dang and Anupam Golder and Asra Ali and Jevin Jiang and Arvind and G. Edward Suh and Tushar Krishna},
year={2025},
eprint={2501.07047},
archivePrefix={arXiv},
primaryClass={cs.CR},
url={https://arxiv.org/abs/2501.07047},
}
++CROSS is Deployed in Google TPU Cloud
++CROSS won 2rd place at DAC university demo
++CROSS won the GT NEXT Award
FEATHER: A Reconfigurable Accelerator with Data Reordering Support for Low-Cost On-Chip Dataflow Switching
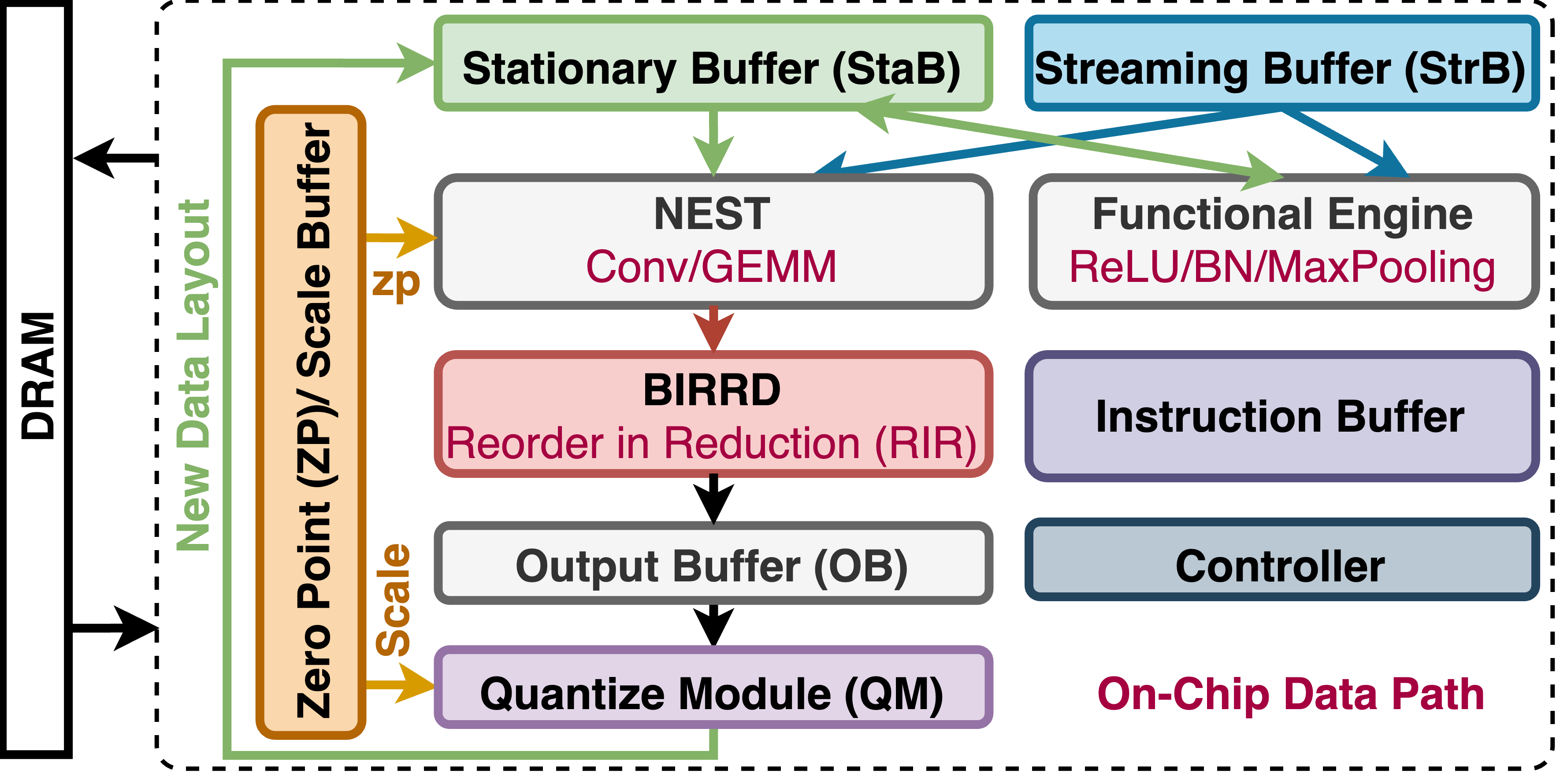
The inference efficiency of diverse ML models over spatial accelerators boils down to the execution of different dataflows (i.e. different tiling, ordering, parallelism, and shapes). Using the optimal dataflow for every layer of workload can reduce latency by up to two orders of magnitude over a suboptimal dataflow. Unfortunately, reconfiguring hardware for different dataflows involves on-chip data layout reordering and datapath reconfigurations, leading to non-trivial overhead that hinders ML accelerators from exploiting different dataflows, resulting in suboptimal performance. To address this challenge, we propose FEATHER, an innovative accelerator that leverages a novel spatial array termed NEST and a novel multi-stage reduction network called BIRRD for performing flexible data reduction with layout reordering under the hood, enabling seamless switching between optimal dataflows with negligible latency and resources overhead. For systematically evaluating the performance interaction between dataflows and layouts, we enhance Timeloop, a state-of-the-art dataflow cost modeling and search framework, with layout assessment capabilities, and term it as Layoutloop. We model FEATHER into Layoutloop and also deploy FEATHER end-to-end on the edge ZCU104 FPGA. FEATHER delivers 1.27~2.89x inference latency speedup and 1.3~6.43x energy efficiency improvement compared to various SoTAs like NVDLA, SIGMA and Eyeriss under ResNet-50 and MobiletNet-V3 in Layoutloop. On practical FPGA devices, FEATHER achieves 2.65/3.91x higher throughput than Xilinx DPU/Gemmini. Remarkably, such performance and energy efficiency enhancements come at only 6% area over a fixed-dataflow Eyeriss-like accelerator. Our code is available at https://github.com/maeri-project/FEATHER.
@inproceedings{tong2024FEATHER,
author = {Tong, Jianming and Itagi, Anirudh and Chatarasi, Parsanth and Krishna, Tushar},
title = {FEATHER: A Reconfigurable Accelerator with Data Reordering Support for Low-Cost On-Chip Dataflow Switching},
year = {2024},
publisher = {Association for Computing Machinery},
address = {Argentina},
abstract = {The inference of ML models composed of diverse structures, types, and sizes boils down to the execution of different dataflows (i.e. different tiling, ordering, parallelism, and shapes). Using the optimal dataflow for every layer of workload can reduce latency by up to two orders of magnitude over a suboptimal dataflow. Unfortunately, reconfiguring hardware for different dataflows involves on-chip data layout reordering and datapath reconfigurations, leading to non-trivial overhead that hinders ML accelerators from exploiting different dataflows, resulting in suboptimal performance. To address this challenge, we propose FEATHER, an innovative accelerator that leverages a novel spatial array termed Nest and a novel multi-stage reduction network called BIRRD for performing flexible data reduction with layout reordering under the hood, enabling seamless switching between optimal dataflows with negligible latency and resources overhead. For systematically evaluating the performance interaction between dataflows and layouts, we enhance Timeloop, a state-of-the-art dataflow cost modeling and search framework, with layout assessment capabilities, and term it as Layoutloop. We model FEATHER into Layoutloop and also deploy FEATHER end-to-end on the edge ZCU104 FPGA. FEATHER delivers 1.27~2.89x inference latency speedup and 1.3~6.43x energy efficiency improvement compared to various SoTAs like NVDLA, SIGMA and Eyeriss under ResNet-50 and MobiletNet-V3 in Layoutloop. On practical FPGA devices, FEATHER achieves 2.65/3.91x higher throughput than Xilinx DPU/Gemmini. Remarkably, such performance and energy efficiency enhancements come at only 6% area over a fixed-dataflow Eyeriss-like accelerator.},
booktitle = {Proceedings of the 51th Annual International Symposium on Computer Architecture},
keywords = {flexible accelerator, dataflow-layout coswitching},
location = {Argentina},
series = {ISCA '24}
}
SquareLoop: Explore Optimal Authentication Block Strategy for ML
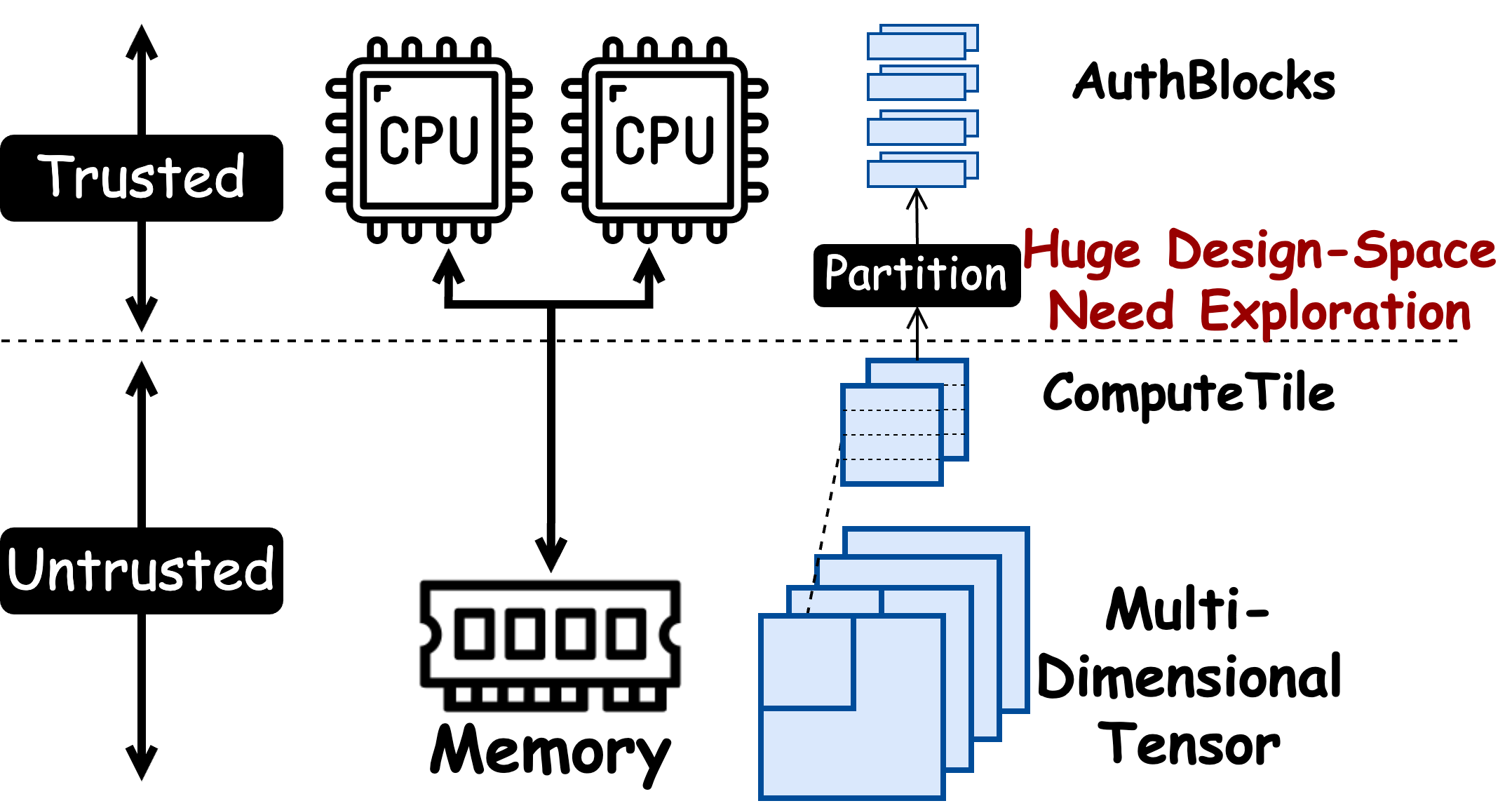
Off-chip memory in ML accelerators is vulnerable to both hardware and software attack, which needs encryption and authentication. Precise performance modeling of it requires (1) representation of authentication blocks (AuthBlock) to cover the full design space of shapes and orientations, and (2) precise memory behavior modeling, as encryption and authentication mainly increase memory traffic. This paper introduces S2Loop, a framework that resolves these challenges by introducing (1) flexible, all-level partitioning based AuthBlocks for ensuring full coverage of the entire design space, (2) a realistic layout-based memory model, and (3) an Mapping-Layout-Authentication co-search algorithm to explore the drastic combinatorial design space to figure out optimal mapping, layout, and AuthBlock shape choice for multi-layer workloads. SquareLoop’s detailed memory model helps find better mapping to achieve 1.32 × speedup on ResNet18 compared to the SotA SecureLoop, and our latency predictions are validated to within 7.3% of an RTL implementation. S2Loop also achieve up-to 1.08 × /1.82 × overall speedup for authenticated ResNet18/MobileNet-V3 on various accelerators with AuthBlock and Mapping co-searching. We open-source S2Loop to provide a powerful and validated tool for designing efficient, secure accelerators at https://github.com/maeri-project/squareloop.
@inproceedings{10.1145/3768725.3768732,
author = {Strzeszynski, Jan and Tong, Jianming and Lee, Kyungmi and Xiong, Nathan and Parashar, Angshuman and Emer, Joel S. and Krishna, Tushar and Yan, Mengjia},
title = {SquareLoop: Explore Optimal Authentication Block Strategy for ML},
year = {2025},
isbn = {9798400721984},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3768725.3768732},
doi = {10.1145/3768725.3768732},
abstract = {Off-chip memory in ML accelerators is vulnerable to both hardware and software attack, which needs encryption and authentication. Precise performance modeling of it requires (1) representation of authentication blocks (AuthBlock) to cover the full design space of shapes and orientations, and (2) precise memory behavior modeling, as encryption and authentication mainly increase memory traffic. This paper introduces S2Loop, a framework that resolves these challenges by introducing (1) flexible, all-level partitioning based AuthBlocks for ensuring full coverage of the entire design space, (2) a realistic layout-based memory model, and (3) an Mapping-Layout-Authentication co-search algorithm to explore the drastic combinatorial design space to figure out optimal mapping, layout, and AuthBlock shape choice for multi-layer workloads. SquareLoop’s detailed memory model helps find better mapping to achieve 1.32 \texttimes{} speedup on ResNet18 compared to the SotA SecureLoop, and our latency predictions are validated to within 7.3\% of an RTL implementation. S2Loop also achieve up-to 1.08 \texttimes{} /1.82 \texttimes{} overall speedup for authenticated ResNet18/MobileNet-V3 on various accelerators with AuthBlock and Mapping co-searching. We open-source S2Loop to provide a powerful and validated tool for designing efficient, secure accelerators at .},
booktitle = {Proceedings of the 14th International Workshop on Hardware and Architectural Support for Security and Privacy},
pages = {37–45},
numpages = {9},
keywords = {machine learning accelerator, performance modeling, memory encryption and authentication},
location = {
},
series = {HASP '25}
}
SCALE-Sim v3: A Modular Cycle-Accurate Systolic Accelerator Simulator for End-to-End System Analysis
We present SCALE-Sim v3, a modular cycle-accurate simulator for systolic-array-based architectures, featuring multi-core architecture with spatio-temporal partitioning, sparsity, DRAM ramulator, precise data layout modeling, and energy and power estimation via Accelergy.
@misc{raj2025scalesimv3modularcycleaccurate,
title={SCALE-Sim v3: A modular cycle-accurate systolic accelerator simulator for end-to-end system analysis},
author={Ritik Raj and Sarbartha Banerjee and Nikhil Chandra and Zishen Wan and Jianming Tong and Ananda Samajdar and Tushar Krishna},
year={2025},
eprint={2504.15377},
archivePrefix={arXiv},
primaryClass={cs.PF},
url={https://arxiv.org/abs/2504.15377},
}
SmartPAF: Accurate Low-Degree Polynomial Approximation of Non-polynomial Operators for Fast Private Inference in Homomorphic Encryption
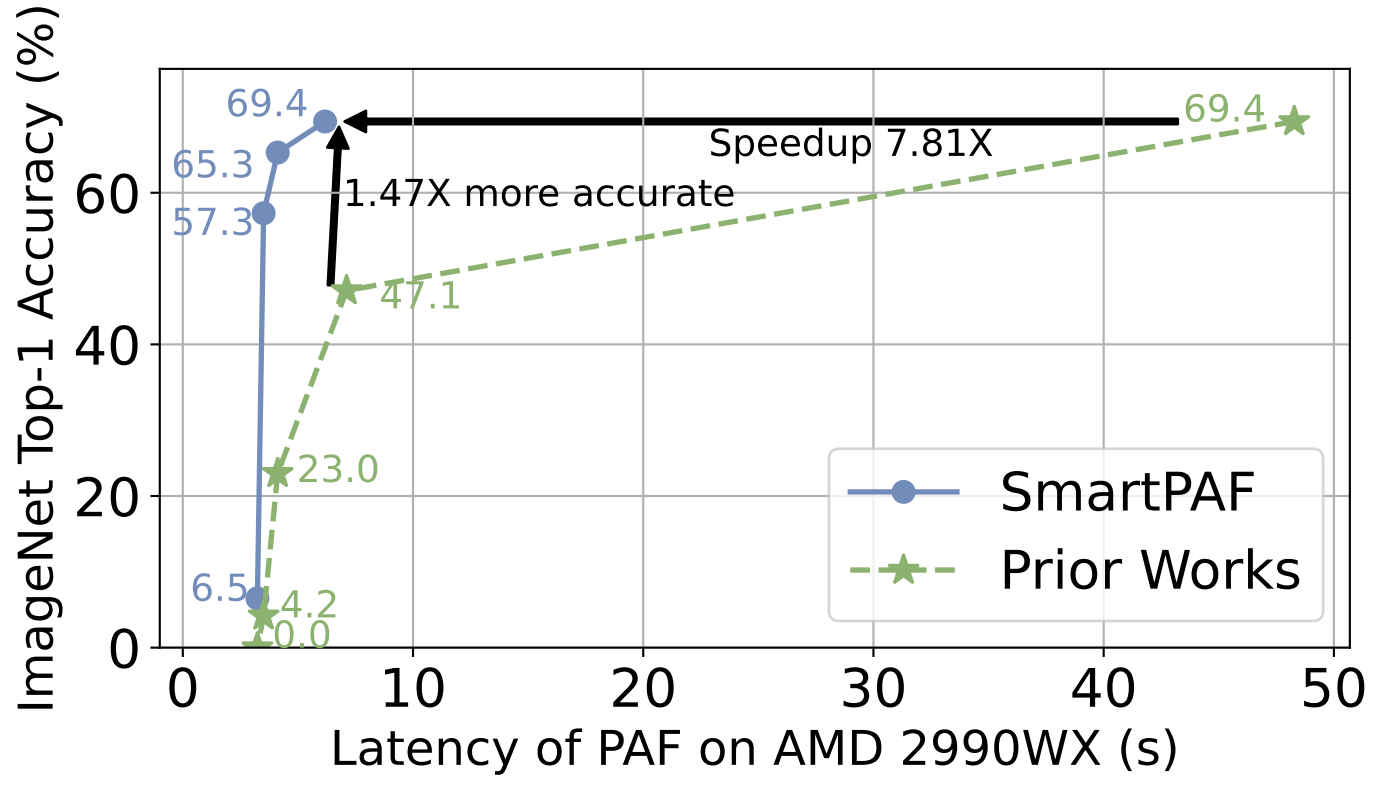
As machine learning (ML) permeates fields like healthcare, facial recognition, and blockchain, the need to protect sensitive data intensifies. Fully Homomorphic Encryption (FHE) allows inference on encrypted data, preserving the privacy of both data and the ML model. However, it slows down non-secure inference by up to five magnitudes, with a root cause of replacing non-polynomial operators (ReLU and MaxPooling) with high-degree Polynomial Approximated Function (PAF). We propose SmartPAF, a framework to replace non-polynomial operators with low-degree PAF and then recover the accuracy of PAF-approximated model through four techniques: (1) Coefficient Tuning (CT) -- adjust PAF coefficients based on the input distributions before training, (2) Progressive Approximation (PA) -- progressively replace one non-polynomial operator at a time followed by a fine-tuning, (3) Alternate Training (AT) -- alternate the training between PAFs and other linear operators in the decoupled manner, and (4) Dynamic Scale (DS) / Static Scale (SS) -- dynamically scale PAF input value within (-1, 1) in training, and fix the scale as the running max value in FHE deployment. The synergistic effect of CT, PA, AT, and DS/SS enables SmartPAF to enhance the accuracy of the various models approximated by PAFs with various low degrees under multiple datasets. For ResNet-18 under ImageNet-1k, the Pareto-frontier spotted by SmartPAF in latency-accuracy tradeoff space achieves 1.42x ~ 13.64x accuracy improvement and 6.79x ~ 14.9x speedup than prior works. Further, SmartPAF enables a 14-degree PAF (f1^2 g_1^2) to achieve 7.81x speedup compared to the 27-degree PAF obtained by minimax approximation with the same 69.4% post-replacement accuracy. Our code is available at \url{https://github.com/EfficientFHE/SmartPAF}
@inproceedings{tong2024accurate,
author={Jianming Tong and Jingtian Dang and Anupam Golder and Callie Hao and Arijit Raychowdhury and Tushar Krishna},
booktitle = {Proceedings of Machine Learning and Systems (MLSys)},
title={Accurate Low-Degree Polynomial Approximation of Non-polynomial Operators for Fast Private Inference in Homomorphic Encryption},
url = {https://arxiv.org/abs/2404.03216},
year = {2024}
}
Hardware-Software co-design for real-time latency-accuracy navigation in tinyML applications
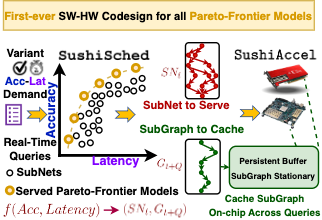
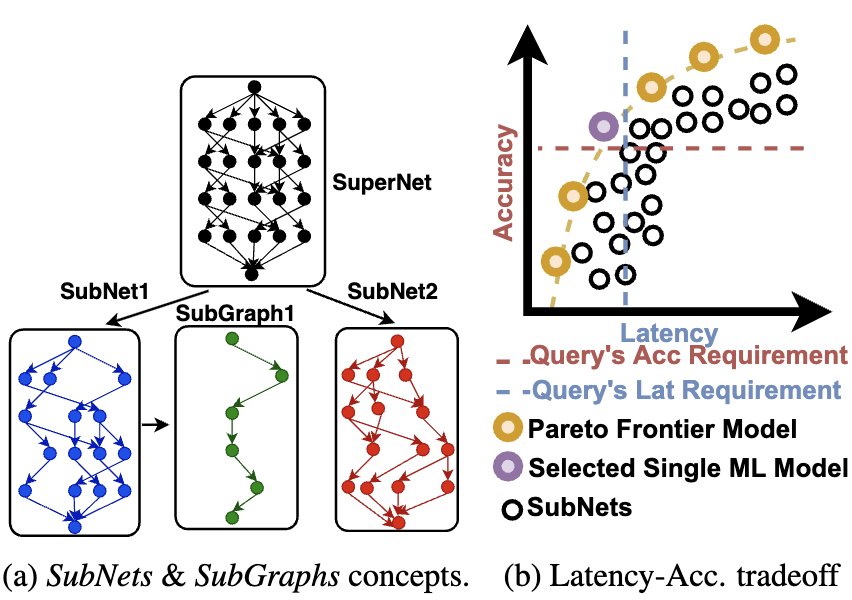
tinyML applications increasingly operate in dynamically changing deployment scenarios, requiring optimizing for both accuracy and latency. Existing methods mainly target a single point in the accuracy/latency tradeoff space---insufficient as no single static point can be optimal under variable conditions. We draw on a recently proposed weight-shared SuperNet mechanism to enable serving a stream of queries that activates different SubNets within a SuperNet. This creates an opportunity to exploit the inherent temporal locality of different queries that use the same SuperNet. We propose a hardware-software co-design called SUSHI that introduces a novel SubGraph Stationary optimization. SUSHI consists of a novel FPGA implementation and a software scheduler that controls which SubNets to serve and what SubGraph to cache in real-time. SUSHI yields up to 32% improvement in latency, 0.98% increase in served accuracy, and achieves up to 78.7% saved off-chip energy across several neural network architectures.
@ARTICLE {10257666,
author = {P. Behnam and J. Tong and A. Khare and Y. Chen and Y. Pan and P. Gadikar and A. Bambhaniya and T. Krishna and A. Tumanov},
journal = {IEEE Micro},
title = {Hardware-Software co-design for real-time latency-accuracy navigation in tinyML applications},
year = {5555},
volume = {},
number = {01},
issn = {1937-4143},
pages = {1-7},
abstract = {tinyML applications increasingly operate in dynamically changing deployment scenarios, requiring optimizing for both accuracy and latency. Existing methods mainly target a single point in the accuracy/latency tradeoff space—insufficient as no single static point can be optimal under variable conditions. We draw on a recently proposed weight-shared SuperNet mechanism to enable serving a stream of queries that activates different SubNets within a SuperNet. This creates an opportunity to exploit the inherent temporal locality of different queries that use the same SuperNet. We propose a hardware-software co-design called SUSHI that introduces a novel SubGraph Stationary optimization. SUSHI consists of a novel FPGA implementation and a software scheduler that controls which SubNets to serve and what SubGraph to cache in real-time. SUSHI yields up to 32% improvement in latency, 0.98% increase in served accuracy, and achieves up to 78.7% saved off-chip energy across several neural network architectures.},
keywords = {kernel;training;real-time systems;optimization;neural networks;system-on-chip;software},
doi = {10.1109/MM.2023.3317243},
publisher = {IEEE Computer Society},
address = {Los Alamitos, CA, USA},
month = {sep}
}
A growing number of applications depend on Machine Learning (ML) functionality and benefits from both higher quality ML predictions and better timeliness (latency) at the same time. A growing body of research in computer architecture, ML, and systems software literature focuses on reaching better latency/accuracy tradeoffs for ML models. Efforts include compression, quantization, pruning, early-exit models, mixed DNN precision, as well as ML inference accelerator designs that minimize latency and energy, while preserving delivered accuracy. All of them, however, yield improvements for a single static point in the latency/accuracy tradeoff space. We make a case for applications that operate in dynamically changing deployment scenarios, where no single static point is optimal. We draw on a recently proposed weight-shared SuperNet mechanism to enable serving a stream of queries that uses (activates) different SubNets within this weight-shared construct. This creates an opportunity to exploit the inherent temporal locality with our proposed SubGraph Stationary (SGS) optimization. We take a hardware-software co-design approach with a real implementation of SGS in SushiAccel and the implementation of a software scheduler SushiSched controlling which SubNets to serve and what to cache in real-time. Combined, they are vertically integrated into SUSHI---an inference serving stack. For the stream of queries, SUSHI yields up to 25% improvement in latency, 0.98% increase in served accuracy. SUSHI can achieve up to 78.7% off-chip energy savings.
@misc{behnam2023subgraph,
title={Subgraph Stationary Hardware-Software Inference Co-Design},
author={Payman Behnam and Jianming Tong and Alind Khare and Yangyu Chen and Yue Pan and Pranav Gadikar and Abhimanyu Rajeshkumar Bambhaniya and Tushar Krishna and Alexey Tumanov},
year={2023},
eprint={2306.17266},
archivePrefix={arXiv},
primaryClass={cs.DC}
}
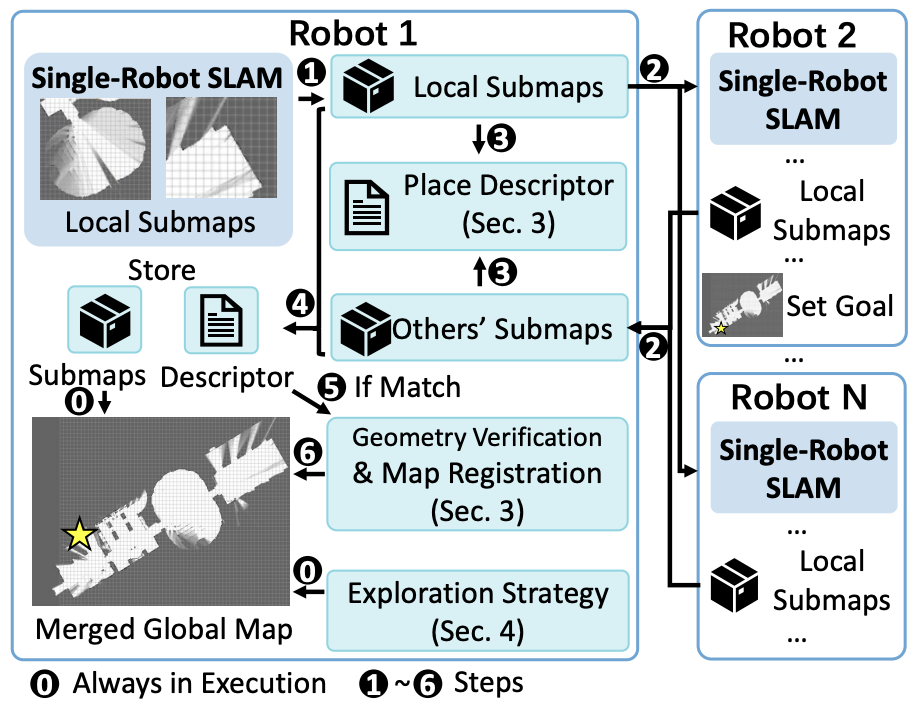
SMMR-explore: Submap-based multi-robot exploration system with multi-robot multi-target potential field exploration method
Collaborative exploration in an unknown environment without external positioning under limited communication is an essential task for multi-robot applications. For inter-robot positioning, various Distributed Simultaneous Localization and Mapping (DSLAM) systems share the Place Recognition (PR) descriptors and sensor data to estimate the relative pose between robots and merge robots’ maps. As maps are constantly shared among robots in exploration, we design a map-based DSLAM framework, which only shares the submaps, eliminating the transfer of PR descriptors and sensor data. Our framework saves 30% of total communication traffic. For exploration, each robot is assigned to get much unknown information about environments with paying little travel cost. As the number of sampled points increases, the goal would change back and forth among sampled frontiers, leading to the downgrade in exploration efficiency and the overlap of trajectories. We propose an exploration strategy based on Multi-robot Multi-target Potential Field (MMPF), which can eliminate goal’s back-and-forth changes, boosting the exploration efficiency by 1.03 ×∼1.62 × with 3 % ∼ 40 % travel cost saved. Our SubMap-based Multi-robot Exploration method (SMMR-Explore) is evaluated on both Gazebo simulator and real robots. The simulator and the exploration framework are published as an open-source ROS project at https://github.com/efc-robot/SMMR-Explore.
@INPROCEEDINGS{9561328,
author={Yu, Jincheng and Tong, Jianming and Xu, Yuanfan and Xu, Zhilin and Dong, Haolin and Yang, Tianxiang and Wang, Yu},
booktitle={2021 IEEE International Conference on Robotics and Automation (ICRA)},
title={SMMR-Explore: SubMap-based Multi-Robot Exploration System with Multi-robot Multi-target Potential Field Exploration Method},
year={2021},
volume={},
number={},
pages={8779-8785},
doi={10.1109/ICRA48506.2021.9561328}}
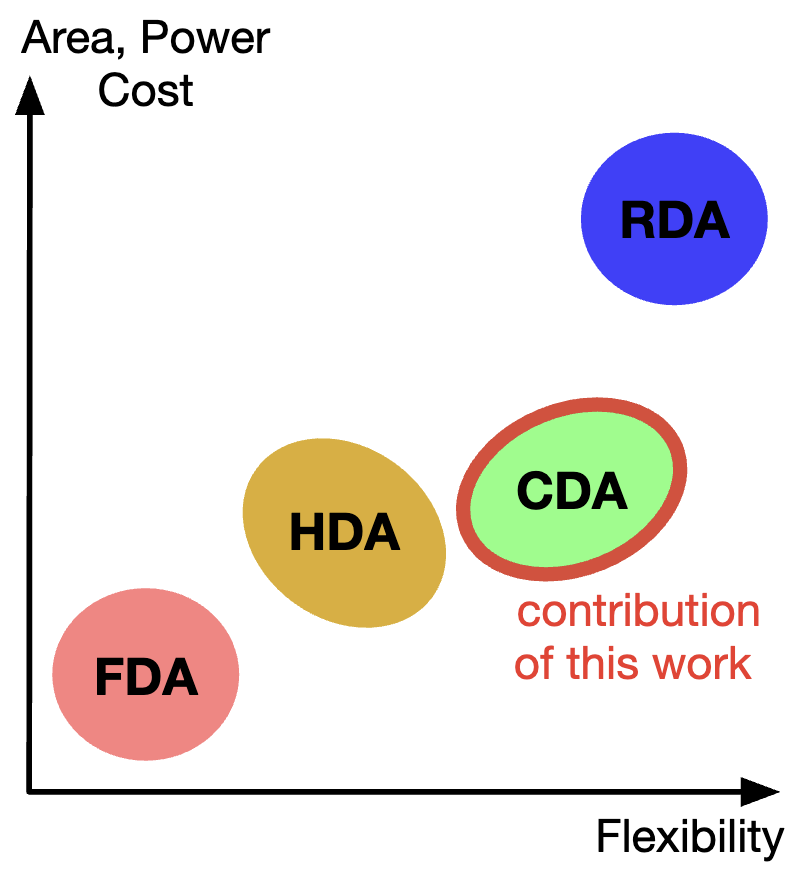
Emerging machine learning (ML) workloads, such as those in AR/VR applications or drones, exhibit real-time multitask multi-model (RT-MTMM) characteristics. These workloads demand efficient executions of diverse combinations of multiple models within strict real-time constraints and tight energy budgets. Consequently, optimizing hardware accelerator design and dataflow choices for such ML models becomes imperative. Flexible dataflows in hardware have been explored to enhance performance and energy efficiency for diverse models. However, this flexibility involves substantial hardware costs, potentially outweighing the performance benefits. While coarse-grained flexible accelerators, including heterogeneous dataflow accelerators [1], have been proposed to mitigate such costs, they may prove suboptimal depending on combinations of models, potentially leading to under-performance of the hardware. Hence, this paper investigates the desired balance between the benefits and costs of flexibility. We present a systematic and quantitative exploration of medium-grained flexible accelerators, demonstrating that constrained yet judicious domain-aware flexibility choices in tile sizes (T), loop order (O), parallel dimensions (P), and array shape (S) can allow RT-MTMM accelerators to achieve comparable real-time performance (×1.06/×1.13) and energy efficiency (×1.09/×1.07) to fully flexible designs with significantly lower area overhead (×0.67×0.91) on edge/mobilescale accelerators.
@INPROCEEDINGS{11096375,
author={Seo, Jamin and Tong, Jianming and Krishna, Tushar and Kwon, Hyoukjun},
booktitle={2025 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS)},
title={Exploring Constrained Dataflow Accelerators for Real-Time Multi-Task Multi-Model Ml Workloads},
year={2025},
volume={},
number={},
pages={1-11},
keywords={Costs;Systematics;Shape;Machine learning;Multitasking;Real-time systems;Energy efficiency;Software;Space exploration;Resource management;Multi-task multi-model machine learning;flexible dataflow;machine learning system},
doi={10.1109/ISPASS64960.2025.00014}}
Collaborative Publications (* Equal Contribution) As Collaborator or Mentor
Real-time Digital RF Emulation – II: A Near Memory Custom Accelerator
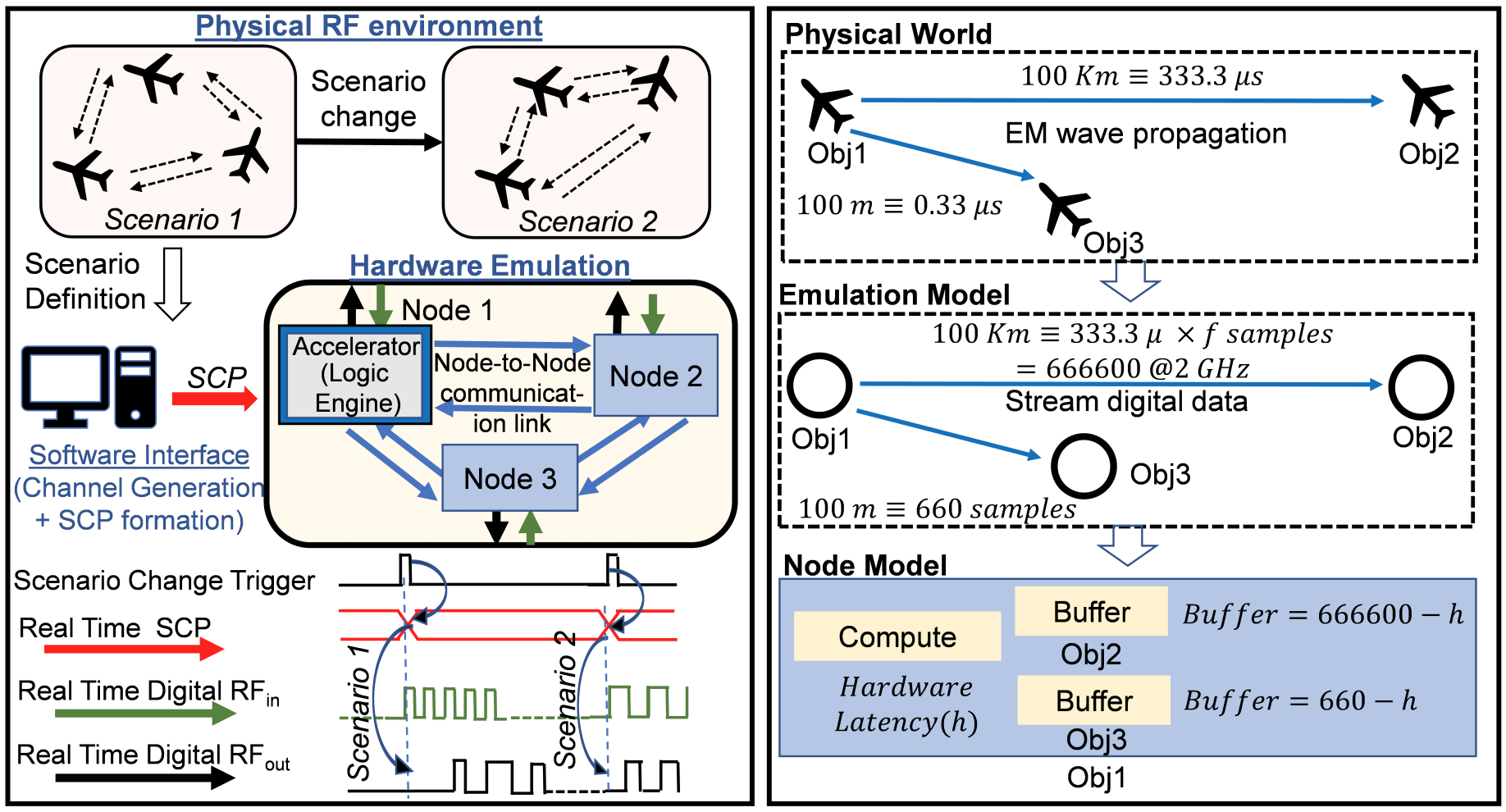
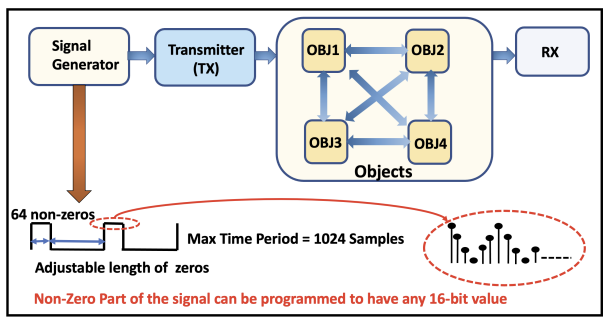
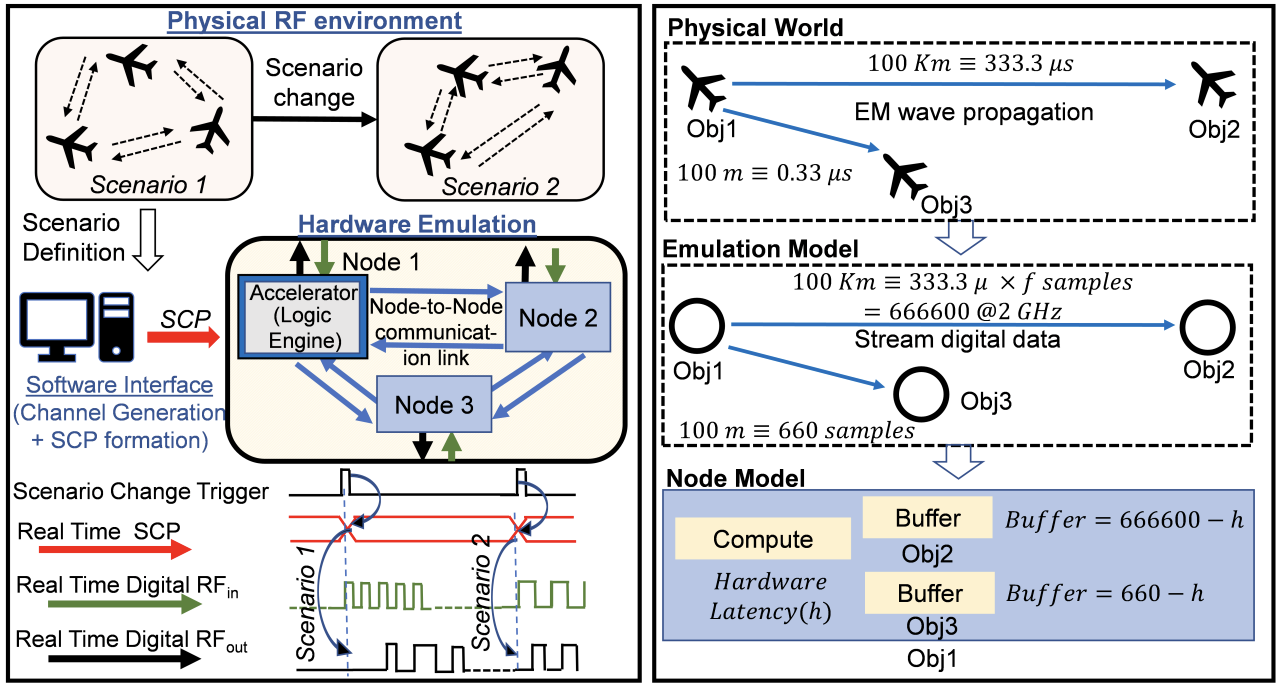
A near memory hardware accelerator, based on a novel direct path computational model, for real-time emulation of radio frequency systems is demonstrated. Our evaluation of hardware performance uses both application-specific integrated circuits (ASIC) and field programmable gate arrays (FPGA) methodologies: 1). The ASIC test-chip implementation, using TSMC 28nm CMOS, leverages distributed autonomous control to extract concurrency in compute as well as low latency. It achieves a 518 MHz per channel bandwidth in a prototype 4-node system. The maximum emulation range supported in this paradigm is 9.5 km with 0.24 μs of per-sample emulation latency. 2). The FPGA-based implementation, evaluated on a Xilinx ZCU104 board, demonstrates a 9-node test case (two Transmitters, one Receiver, and 6 passive reflectors) with an emulation range of 1.13 km to 27.3 km at 215 MHz bandwidth.
@ARTICLE{10672547,
author={Mao, X. and Mukherjee, M. and Mizanur Rahman, N. and DeLude, C. and Driscoll, J. and Sharma, S. and Behnam, P. and Kamal, U. and Woo, J. and Kim, D. and Khan, S. and Tong, J. and Seo, J. and Sinha, P. and Swaminathan, M. and Krishna, T. and Pande, S. and Romberg, J. and Mukhopadhyay, S.},
journal={IEEE Transactions on Radar Systems},
title={Real-time Digital RF Emulation – II: A Near Memory Custom Accelerator},
year={2024},
volume={},
number={},
pages={1-1},
keywords={Radio frequency;Computational modeling;Emulation;Computer architecture;Hardware;Real-time systems;Pulse modulation;hardware accelerators;near-memory;radio frequency emulator;real-time},
doi={10.1109/TRS.2024.3457523}}
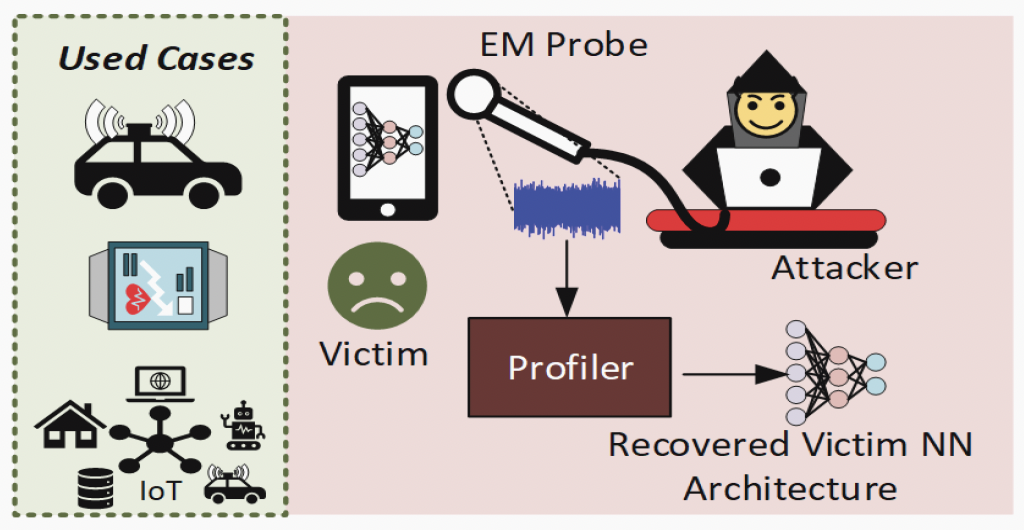
SNATCH: Stealing Neural Network Architecture from ML Accelerator in Intelligent Sensors
The use of Machine Learning (ML) models executing on ML Accelerators (MLA) in Intelligent sensors for feature extraction has garnered substantial interest. The Neural Network (NN) architecture implemented of MLA are intellectual property for the vendors. Along with improved power-efficiency and reduced bandwidth, the hardware based ML models embedded in the sensor also provides additional security against cyber-attacks on the ML. In this paper, we introduce an attack referred as SNATCH which uses a profiling-based side channel attack (SCA) that aims to steal the NN architecture executing on a digital MLA (Deep Learning Processing Unit (DPU) IP by Xilinx). We use electromagnetic side channel leakage from a clone device to create a profiler and then attack the victim's device to steal the NN architecture. Stealing the ML model undermines the intellectual property rights of the vendors of a sensor. Further, it also allows an adversary to mount critical Denial of Service and misuse attack.
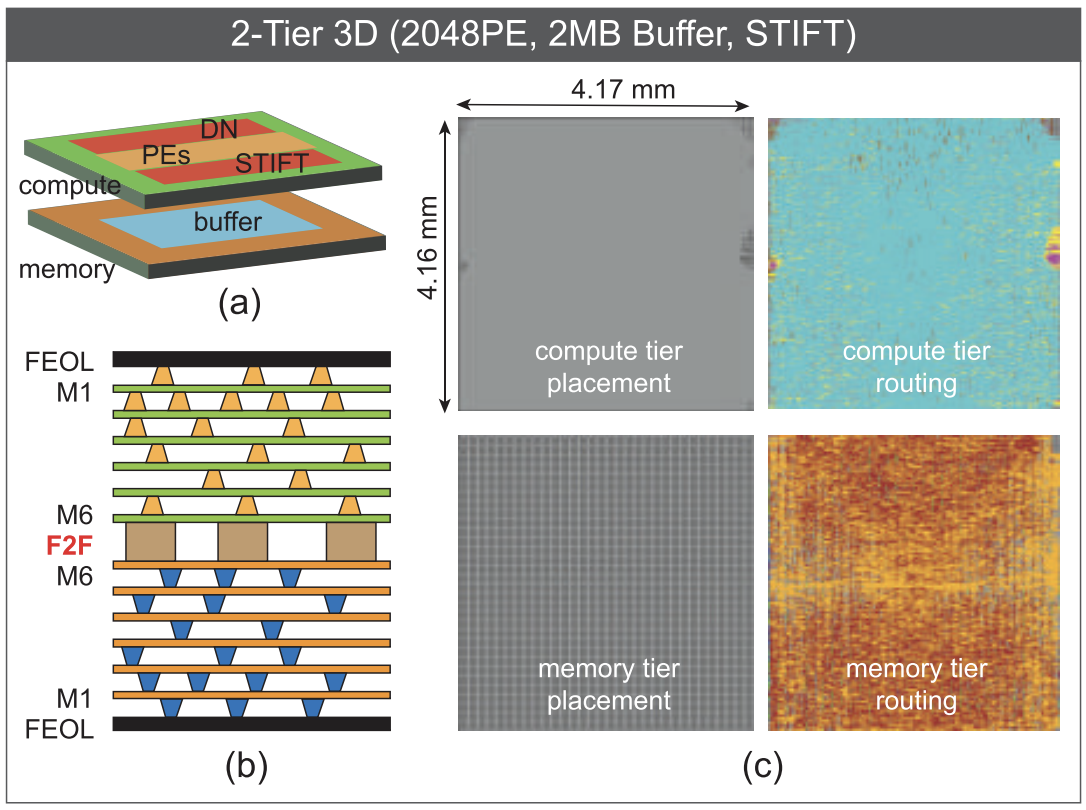
On Continuing DNN Accelerator Architecture Scaling Using Tightly-coupled Compute-on-Memory 3D ICs
This work identifies the architectural and design scaling limits of 2D flexible interconnect DNN accelerators and addresses them with 3D ICs. We demonstrate how scaling up a baseline 2D accelerator in the X/Y dimension fails and how vertical stacking effectively overcomes the failure. We designed multi-tier accelerators that are 1.67X faster than the 2D design. Using our 3D architecture and circuit co-design methodology, we improve throughput, energy-efficiency, and area-efficiency by up to 5X, 1.2X, and 3.9X, respectively, over 2D counterparts. The IR-drop in our 3D designs is within 10.7% of VDD, and the temperature variation is within 12˚C.
@ARTICLE{10221779,
author={Murali, Gauthaman and Iyer, Aditya and Zhu, Lingjun and Tong, Jianming and Martínez, Francisco Muñoz and Srinivasa, Srivatsa Rangachar and Karnik, Tanay and Krishna, Tushar and Lim, Sung Kyu},
journal={IEEE Transactions on Very Large Scale Integration (VLSI) Systems},
title={On Continuing DNN Accelerator Architecture Scaling Using Tightly Coupled Compute-on-Memory 3-D ICs},
year={2023},
volume={},
number={},
pages={1-11},
doi={10.1109/TVLSI.2023.3299564}}
FPGA-Based High-Performance Real-Time Emulation of Radar System using Direct Path Compute Model
This paper proposes a Field-Programmable Gate Array (FPGA) based platform for real-time emulation of Radio Frequency (RF) signal interactions among radars and reflectors. Unlike conventional tapped-delay Finite-Impulse-Response (FIR) models, the paper presents an FPGA realization of Direct Path Compute model for RF signal propagation. Experimental results on a Xilinx ZCU104 board demonstrate a 5-platform system of the emulation range of 2.78km to 27.3km at 180 MHz bandwidth.
@INPROCEEDINGS{10187950,
author={Mao, X. and Mukherjee, M. and Rahman, N. M. and Kamal, U. and Sharma, S. and Behnam, P. and Tong, J. and Driscoll, J. and Krishna, T. and Romberg, J. and Mukhopadhyay, S.},
booktitle={2023 IEEE/MTT-S International Microwave Symposium - IMS 2023},
title={FPGA-Based High-Performance Real-Time Emulation of Radar System Using Direct Path Compute Model},
year={2023},
volume={},
number={},
pages={419-422},
keywords={Radio frequency;Microwave measurement;Computational modeling;Emulation;RF signals;Radar;Bandwidth;RF emulation;direct path compute model;FPGA;real-time},
doi={10.1109/IMS37964.2023.10187950}}
A High Performance Computing Architecture for Real-Time Digital Emulation of RF Interactions
A high performance architecture for emulating realtime radio frequency systems is presented. The architecture is developed based on a novel compute model and uses nearmemory techniques coupled with highly distributed autonomous control to simultaneously optimize throughput and minimize latency. A cycle level C++ based simulator is used to validate the proposed architecture with simulation of complex RF scenarios.
@INPROCEEDINGS{10149577,
author={Mukherjee, Mandovi and Rahman, Nael Mizanur and DeLude, Coleman and Driscoll, Joseph and Kamal, Uday and Woo, Jongseok and Seo, Jamin and Sharma, Sudarshan and Mao, Xiangyu and Behnam, Payman and Khan, Sharjeel and Kim, Daehyun and Tong, Jianming and Sinha, Prachi and Pande, Santosh and Krishna, Tushar and Romberg, Justin and Swaminathan, Madhavan and Mukhopadhyay, Saibal},
booktitle={2023 IEEE Radar Conference (RadarConf23)},
title={A High Performance Computing Architecture for Real-Time Digital Emulation of RF Interactions},
year={2023},
volume={},
number={},
pages={1-6},
doi={10.1109/RadarConf2351548.2023.10149577}}
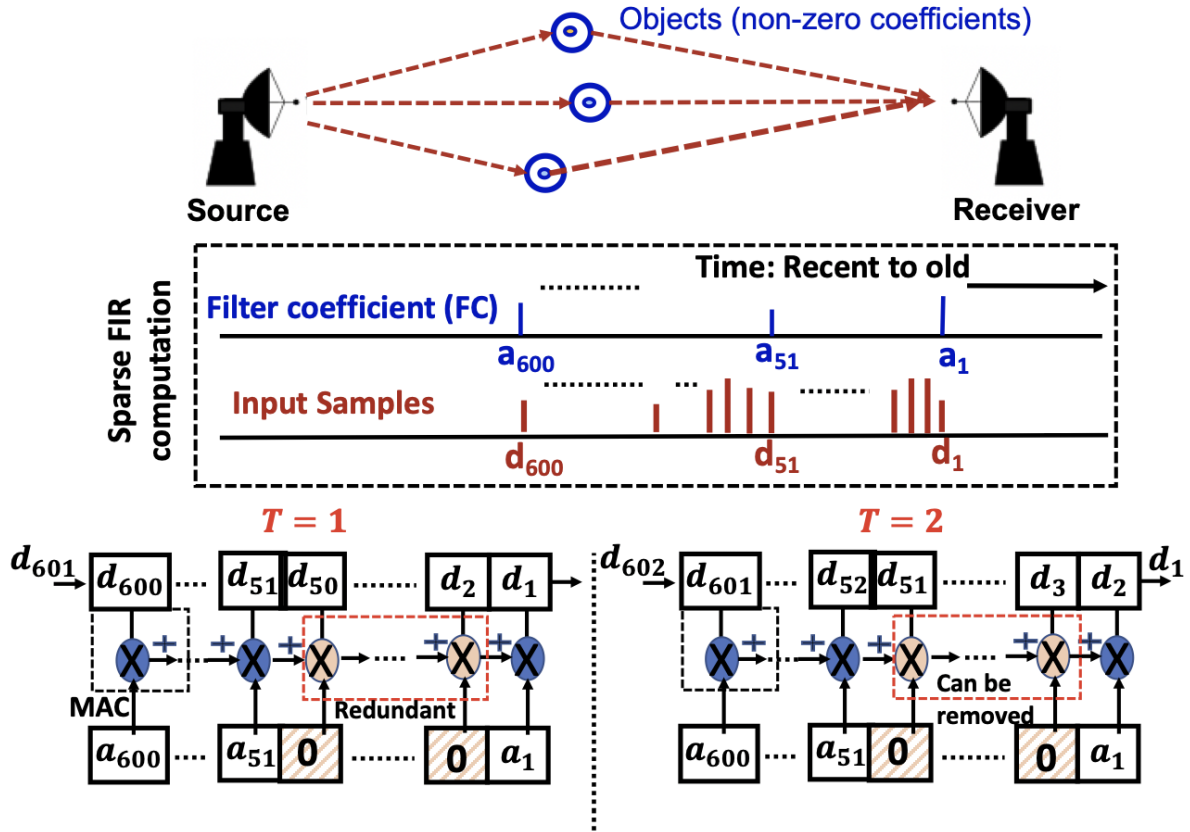
A Configurable Architecture for Efficient Sparse FIR Computation in Real-time Radio Frequency Systems
A low-latency and high-throughput, configurable architecture for computing sparse Finite Impulse Response in real-time Radio Frequency domain is proposed. The massively parallel architecture uses distributed control in association with near-memory techniques to optimize area and power. It supports configurability in filter tap locations and handling of locally dense taps, making it more adaptable to Radio Frequency environments.
@INPROCEEDINGS{9865486,
author={Seo, Jamin and Mukherjee, Mandovi and Rahman, Nael Mizanur and Tong, Jianming and DeLude, Coleman and Krishna, Tushar and Romberg, Justin and Mukhopadhyay, Saibal},
booktitle={2022 IEEE/MTT-S International Microwave Symposium - IMS 2022},
title={A Configurable Architecture for Efficient Sparse FIR Computation in Real-time Radio Frequency Systems},
year={2022},
volume={},
number={},
pages={998-1001},
doi={10.1109/IMS37962.2022.9865486}}
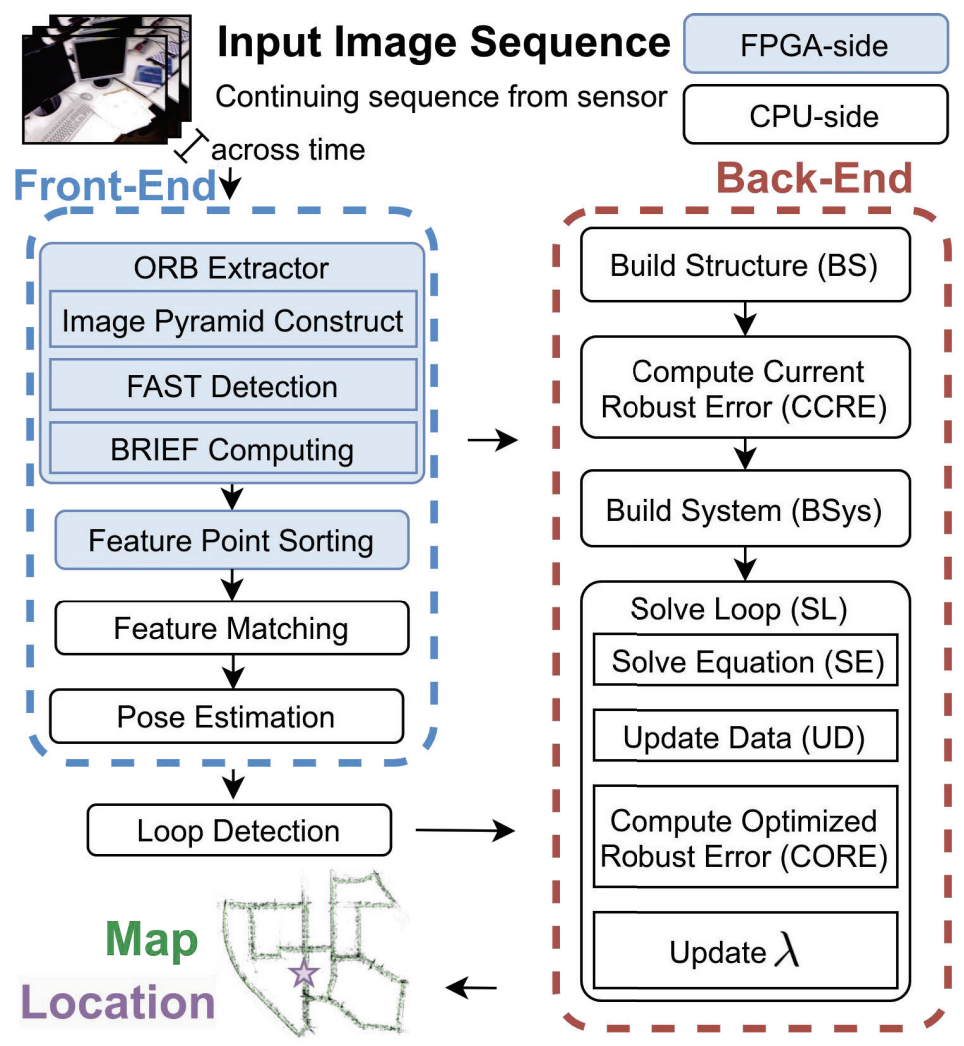
ac2SLAM: FPGA Accelerated High-Accuracy SLAM with Heapsort and Parallel Keypoint Extractor
In order to fulfill the rich functions of the application layer, robust and accurate Simultaneous Localization and Mapping (SLAM) technique is very critical for robotics. However, due to the lack of sufficient computing power and storage capacity, it is challenging to delpoy high-accuracy SLAM in embedded devices efficiently. In this work, we propose a complete acceleration scheme, termed ac 2 SLAM, based on the ORB-SLAM2 algorithm including both front and back ends, and implement it on an FPGA platform. Specifically, the proposed ac 2 SLAM features with: 1) a scalable and parallel ORB extractor to extract sufficient keypoints and scores for throughput matching with 4% error, 2) a PingPong heapsort component (pp-heapsort) to select the significant keypoints, that could achieve single-cycle initiation interval to reduce the amount of data transfer between accelerator and the host CPU, and 3) the potential parallel acceleration strategies for the back-end optimization. Compared with running ORB-SLAM2 on the ARM processor, ac 2 SLAM achieves 2.1 × and 2.7 × faster in the TUM and KITTI datasets, while maintaining 10% error of SOTA eSLAM. In addition, the FPGA accelerated front-end achieves 4.55 × and 40 × faster than eSLAM and ARM. The ac 2 SLAM is fully open-sourced at https://github.com/SLAM-Hardware/acSLAM.
@INPROCEEDINGS{9609808,
author={Wang, Cheng and Liu, Yingkun and Zuo, Kedai and Tong, Jianming and Ding, Yan and Ren, Pengju},
booktitle={2021 International Conference on Field-Programmable Technology (ICFPT)},
title={ac2SLAM: FPGA Accelerated High-Accuracy SLAM with Heapsort and Parallel Keypoint Extractor},
year={2021},
volume={},
number={},
pages={1-9},
doi={10.1109/ICFPT52863.2021.9609808}}
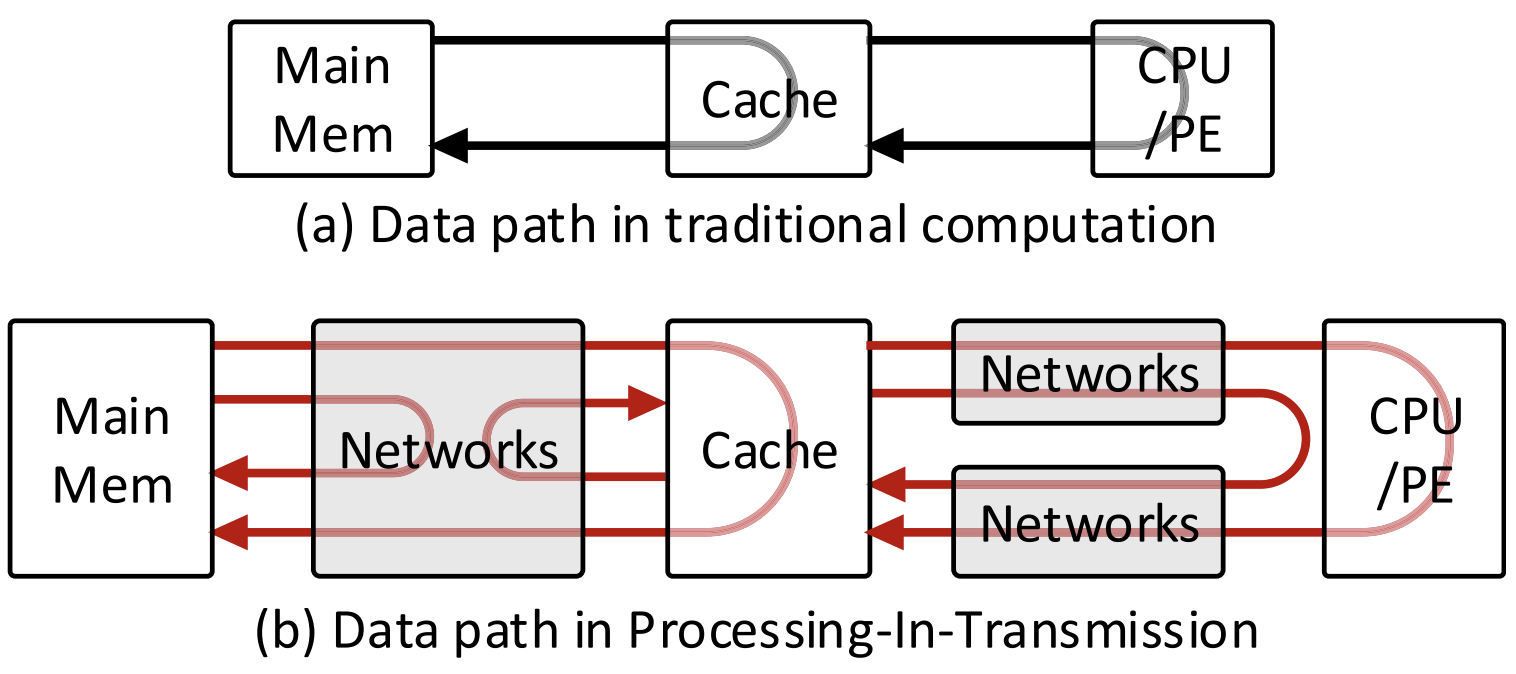
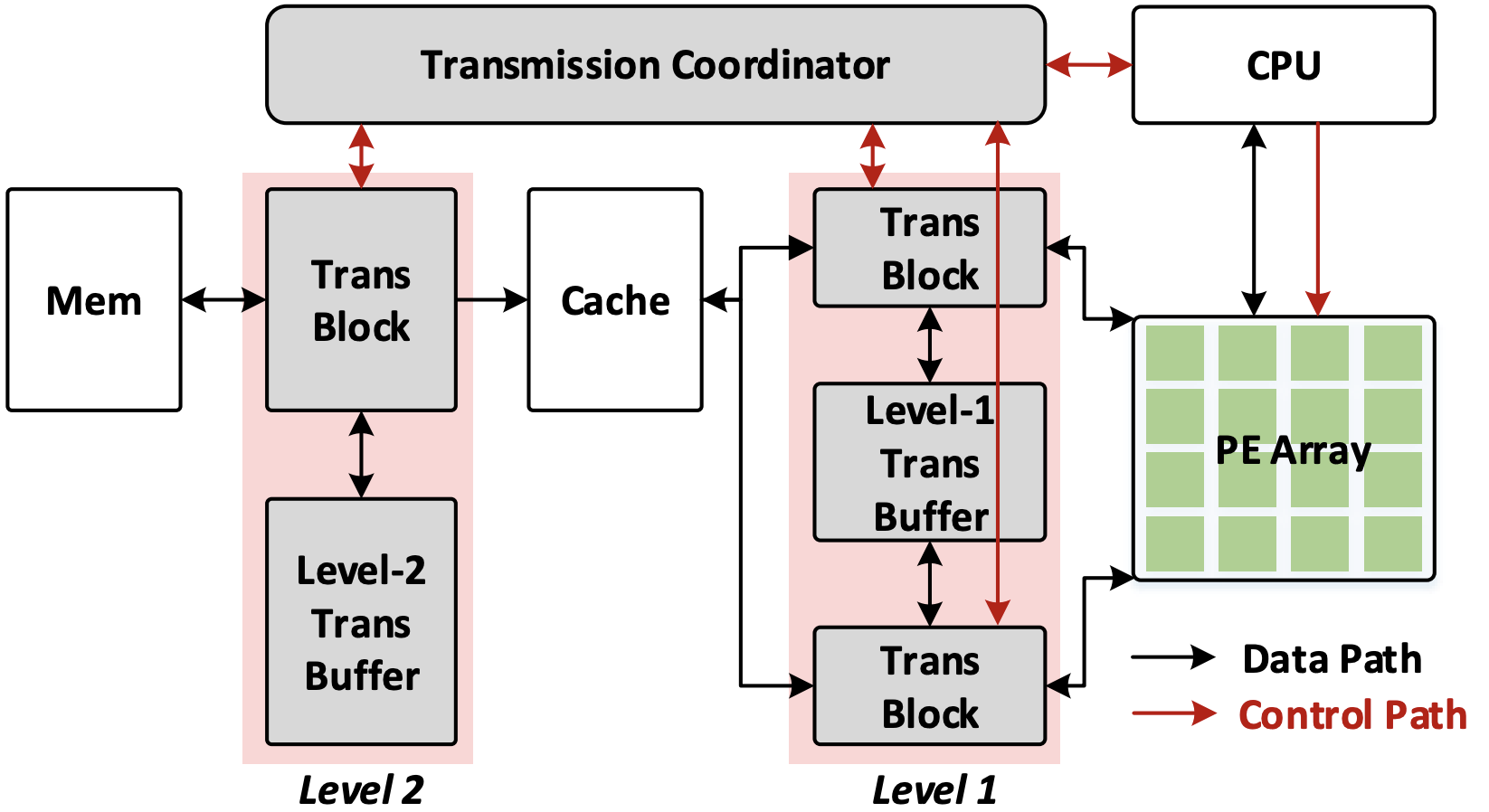
PIT: Processing-In-Transmission with Fine-Grained Data Manipulation Networks
In the domain of data parallel computation, most works focus on data flow optimization inside the PE array and favorable memory hierarchy to pursue the maximum parallelism and efficiency, while the importance of data contents has been overlooked for a long time. As we observe, for structured data, insights on the contents (i.e., their values and locations within a structured form) can greatly benefit the computation performance, as fine-grained data manipulation can be performed. In this paper, we claim that by providing a flexible and adaptive data path, an efficient architecture with capability of fine-grained data manipulation can be built. Specifically, we design SOM, a portable and highly-adaptive data transmission network, with the capability of operand sorting, non-blocking self-route ordering and multicasting. Based on SOM, we propose the processing-in-transmission architecture (PITA), which extends the traditional SIMD architecture to perform some fundamental data processing during its transmission, by embedding multiple levels of SOM networks on the data path. We evaluate the performance of PITA in two irregular computation problems. We first map the matrix inversion task onto PITA and show considerable performance gain can be achieved, resulting in 3x-20x speedup against Intel MKL, and 20x-40x against cuBLAS. Then we evaluate our PITA on sparse CNNs. The results indicate that PITA can greatly improve computation efficiency and reduce memory bandwidth pressure. We achieved 2x-9x speedup against several state-of-art accelerators on sparse CNN, where nearly 100 percent PE efficiency is maintained under high sparsity. We believe the concept of PIT is a promising computing paradigm that can enlarge the capability of traditional parallel architecture.
@ARTICLE{9311185,
author={Zong, Pengchen and Xia, Tian and Zhao, Haoran and Tong, Jianming and Li, Zehua and Zhao, Wenzhe and Zheng, Nanning and Ren, Pengju},
journal={IEEE Transactions on Computers},
title={PIT: Processing-In-Transmission With Fine-Grained Data Manipulation Networks},
year={2021},
volume={70},
number={6},
pages={877-891},
doi={10.1109/TC.2020.3048233}}
COCOA: Content-Oriented Configurable Architecture Based on Highly-Adaptive Data Transmission Networks
Proceedings of the 2020 on Great Lakes Symposium on VLSI (GLSVLSI), 2020.
Insight: Adding NoC between Mem-Cache-CPU for supporting Sorting, Ordering and Multicasting (SOM) could boost 25X CPU perfromance for matrix inversion.
In domain of parallel computation, most works focus on optimizing PE organization or memory hierarchy to pursue the maximum efficiency, while the importance of data contents has been overlooked for a long time. Actually for structured data, insights on data contents (i.e. values and locations within a structured form) can greatly benefit the computation performance, as fine-grained data manipulation can be performed. In this paper, we claim that by providing a flexible and adaptive data path, an efficient architecture with capability of fine-grained data manipulation can be built. Specifically, we propose COCOA, a novel content-oriented configurable architecture, which integrates multi-functional data reorganization networks in traditional computing scheme to handle the contents of data during the transmission path, so that they can be processed more efficiently. We evaluate COCOA on various problems: complex matrix algorithm (matrix inversion) and sparse DNN. The results indicates that COCOA is versatile enough to achieve high computation efficiency in both cases.
@inproceedings{10.1145/3386263.3406924,
author = {Xia, Tian and Zong, Pengchen and Zhao, Haoran and Tong, Jianming and Zhao, Wenzhe and Zheng, Nanning and Ren, Pengju},
title = {COCOA: Content-Oriented Configurable Architecture Based on Highly-Adaptive Data Transmission Networks},
year = {2020},
isbn = {9781450379441},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3386263.3406924},
doi = {10.1145/3386263.3406924},
abstract = {In domain of parallel computation, most works focus on optimizing PE organization or memory hierarchy to pursue the maximum efficiency, while the importance of data contents has been overlooked for a long time. Actually for structured data, insights on data contents (i.e. values and locations within a structured form) can greatly benefit the computation performance, as fine-grained data manipulation can be performed. In this paper, we claim that by providing a flexible and adaptive data path, an efficient architecture with capability of fine-grained data manipulation can be built. Specifically, we propose COCOA, a novel content-oriented configurable architecture, which integrates multi-functional data reorganization networks in traditional computing scheme to handle the contents of data during the transmission path, so that they can be processed more efficiently. We evaluate COCOA on various problems: complex matrix algorithm (matrix inversion) and sparse DNN. The results indicates that COCOA is versatile enough to achieve high computation efficiency in both cases.},
booktitle = {Proceedings of the 2020 on Great Lakes Symposium on VLSI},
pages = {253–258},
numpages = {6},
keywords = {transmission network, computing architecture, high-performance computing, data reorgonization},
location = {Virtual Event, China},
series = {GLSVLSI '20}
}
Workshops
A Reconfigurable Accelerator with Data Reordering Support for Low-Cost On-Chip Dataflow Switching
The increasing prevalence of Machine Learning (ML) in various applications has led to the emergence of ML models with diverse structures, types and sizes. The ML model inference boils down to the execution of different dataflows (tiling, ordering, parallelism, and shapes), and using the optimal dataflow can reduce latency by up to two orders of magnitude over an inefficient one. Unfortunately, reconfiguring hardware for different dataflows involves on-chip data reordering and datapath reconfigurations, leading to non-trivial overheads that hinder ML accelerators from exploiting different dataflows, resulting in suboptimal performance. To address this challenge, we propose LAMBDA, an innovative accelerator that leverages a novel multi-stage reduction network called Additive Folded Fat Tree (AFFT) for reordering data in data reduction (RIR), enabling seamless switching between optimal dataflows with negligible latency and resources overhead. LAMBDA creates an opportunity to change the optimal dataflows at the granularity of layers without incurring additional latency overhead, and to explore the optimal dataflows on the real hardware with faster and more precise evaluation results. LAMBDA demonstrates a 0.5~2X speed up in end-to-end inference latency than the SotA Xilinx DPU on Xilinx ZCU 104 embedded FPGA board.
ReLU-FHE: Low-cost Accurate ReLU Polynoimal Approximation in Fully Homomorphic Encryption Based ML Inference
Machine learning (ML) is getting more pervasive. Wide adoption of ML in healthcare, facial recognition, and blockchain involves private and sensitive data. One of the most promising candidates for inference on encrypted data, termed Fully Homomorphic Encryption (FHE), preserves the privacy of both data and the ML model. However, it slows down plaintext inference by six magnitudes, with a root cause of replacing non-polynomial operators with latency-prohibitive 27-degree Polynomial Approximated Function (PAF). While prior research has investigated low-degree PAFs, naive stochastic gradient descent (SGD) training fails to converge on PAFs with degrees higher than 5, leading to limited accuracy compared to the state-of-the-art 27-degree PAF. Therefore, we propose four training techniques to enable convergence in the post-approximation model using PAFs with an arbitrary degree, including (1) Dynamic Scaling (DS) and Static Scaling (SS) to enable minimal approximation error during approximation, (2) Coefficient Tuning (CT) to obtain a good initial coefficient value for each PAF, (3) Progressive Approximation (PA) to simply the two-variable regression optimization problem into single-variable for fast and easy convergence, and (4) Alternate Training (AT) to retraining the post-replacement PAFs and other linear layers in a decoupled divide-and-conquer manner. A combination of DS/SS, CT, PA, and AT enables the exploration of accuracy-latency space for FHEdomain ReLU replacement. Leveraging the proposed techniques, we propose a systematic approach (PAF-FHE) to enable low-degree PAF to demonstrate the same accuracy as SotA high-degree PAFs. We evaluated PAFs with various degrees on different models and variant datasets, and PAF-FHE consistently enables low-degree PAF to achieve higher accuracy than SotA PAFs. Specifically, for ResNet-18 under the ImageNet-1k dataset, our spotted optimal 12-degree PAF reduces 56% latency compared to the SotA 27-degree PAF with the same post-replacement accuracy (69.4%). While as for VGG-19 under the CiFar-10 dataset, optimal 12-degree PAF achieves even 0.84% higher accuracy with 72% latency saving. Our code is open-sourced at: https://github.com/TorchFHE/PAF-FHE.
@misc {PPR:PPR658940,
Title = {PAF-FHE: Low-Cost Accurate Non-Polynomial Operator Polynomial Approximation in Fully Homomorphic Encryption Based ML Inference},
Author = {Dang, Jingtian and Tong, Jianming and Golder, Anupam and Raychowdhury, Arijit and Hao, Cong and Krishna, Tushar},
DOI = {10.21203/rs.3.rs-2910088/v1},
Abstract = {Machine learning (ML) is getting more pervasive. Wide adoption of ML in healthcare, facial recognition, and blockchain involves private and sensitive data. One of the most promising candidates for inference on encrypted data, termed Fully Homomorphic Encryp-tion (FHE), preserves the privacy of both data and the ML model. However, it slows down plaintext inference by six magnitudes, with a root cause of replacing non-polynomial operators with latency-prohibitive 27-degree Polynomial Approximated Function (PAF). While prior research has investigated low-degree PAFs, naive stochastic gradient descent (SGD) training fails to converge on PAFs with degrees higher than 5, leading to limited accuracy compared to the state-of-the-art 27-degree PAF. Therefore, we propose four training techniques to enable convergence in the post-approximation model using PAFs with an arbitrary degree, including (1) Dynamic Scaling (DS) and Static Scaling (SS) to enable minimal approximation error during approximation, (2) Coefficient Tuning (CT) to obtain a good initial coefficient value for each PAF, (3) Progressive Approximation (PA) to simply the two-variable regression optimization problem into single-variable for fast 1 and easy convergence, and (4) Alternate Training (AT) to retraining the post-replacement PAFs and other linear layers in a decoupled divide-and-conquer manner. A combination of DS/SS, CT, PA, and AT enables the exploration of accuracy-latency space for FHE-domain ReLU replacement. Leveraging the proposed techniques, we propose a systematic approach (PAF-FHE) to enable low-degree PAF to demonstrate the same accuracy as SotA high-degree PAFs. We evaluated PAFs with various degrees on different models and variant datasets, and PAF-FHE consistently enables low-degree PAF to achieve higher accuracy than SotA PAFs. Specifically, for ResNet-18 under the ImageNet-1k dataset, our spotted optimal 12-degree PAF reduces 56% latency compared to the SotA 27-degree PAF with the same post-replacement accuracy (69.4%). While as for VGG-19 under the CiFar-10 dataset, optimal 12-degree PAF achieves even 0.84% higher accuracy with 72% latency saving. Our code is open-sourced at: https://github.com/TorchFHE/PAF-FHE},
Publisher = {Research Square},
Year = {2023},
URL = {https://doi.org/10.21203/rs.3.rs-2910088/v1},
}
FastSwtich: Enabling Real-time DNN Switching via Weight-Sharing
A growing number of applications depend on Machine Learning (ML) functionality and benefits from both higher quality ML predictions and better timeliness (latency) at the same time. A growing body of research in computer architecture, ML, and systems software literature focuses on reaching better latency/accuracy tradeoffs for ML models. Efforts include compression, quantization, pruning, early-exit models, mixed DNN precision, as well as ML inference accelerator designs that minimize latency and energy, while preserving delivered accuracy. All of them, however, yield improvements for a single static point in the latency/accuracy tradeoff space. We make a case for applications that operate in dynamically changing deployment scenarios, where no single static point is optimal. We draw on a recently proposed weight-shared SuperNet mechanism to enable serving a stream of queries that uses (activates) different SubNets within this weight-shared construct. This creates an opportunity to exploit the inherent temporal locality with our proposed SubGraph Stationary (SGS) optimization. We take a hardware-software co-design approach with a real implementation of SGS in SushiAccel and the implementation of a software scheduler SushiSched controlling which SubNets to serve and what to cache in real-time. Combined, they are vertically integrated into SUSHI---an inference serving stack. For the stream of queries, SUSHI yields up to 25% improvement in latency, 0.98% increase in served accuracy. SUSHI can achieve up to 78.7% off-chip energy savings.
Stay in tune
Education
Georgia Institute of Technology, USA
Ph.D. in Computer Science
• Jan. 2021 to Present
Advisor: Prof. Tushar Krishna
Georgia Institute of Technology, USA
MS. in Computer Science
• Jan. 2021 to May 2024
Advisor: Prof. Tushar Krishna
Xi'an Jiaotong University, China
B.E. in Electrical Engineering and Automation (EE)
• Sep. 2016 to Jun
2020
Advisor: Prof. Pengju Ren
Experience
Google, USA
Student Researcher
• Aug. 2024 to Apr. 2025
Host: Asra AliJevin Jiang
Massachusetts Institute of Technology, USA
Research Associative
• Feb. 2024 to Feb. 2025
Advisor: Prof. Tushar Krishna , Host: Prof. Arvind
Rivos Inc., Mountain View CA
Ph.D. Intern in Computer Architecture
• May. 2023 to Aug 2023
Pacific Northwest National Lab (PNNL), Battelle WA
Research Intern in Computer Architecture
• Jun. 2022 to Aug
2022
Alibaba DAMO Academy, Beijing
Research Intern in Fully Homormophic Encryption Accelerator • Jul. 2021 to
Aug. 2021
Tsinghua University, Beijing
(Visiting Student) Research Assistant in Robotics • Aug. 2020 to
Jan. 2021
Advisor: Prof. Yu Wang
Book
On-chip Network (Chinese)
Translator Abstract
This book targets engineers and researchers familiar with basic computer architecture concepts who are interested in learning about on-chip networks. This work is designed to be a short synthesis of the most critical concepts in on-chip network design. It is a resource for both understanding on-chip network basics and for providing an overview of state of-the-art research in on-chip networks.
[purchase translated version] [English version -- Free for University] [obtain original version]